
elektro AUTOMATION: Welche Gründe sprechen für die Integration von KI-Algorithmen in lokale Anwendungen bzw. Steuerungen oder Edge-Devices? Welche Vorteile ergeben sich gegenüber cloudbasierten Lösungen und welche Rolle spielt das Thema Daten-Sicherheit?
Ashkan Ashouriha (Rockwell Automation): Inzwischen steckt viel Intelligenz in den Komponenten, die zum einen die Vorverarbeitung der Daten und zum andern schon selbst Steuerungsfunktionen übernehmen. Das Project Sherlock AI für unsere ControlLogix-Plattform nutzt eine eigenentwickelte ‚Machine learning Engine‘, die auf physikalischen Modellen basiert. Der KI (englisch AI) wird lediglich nur mitgeteilt, welche Prozessdaten für den Kunden relevant sind, und sie fängt selbstständig an, diese zu überwachen, um zu lernen. Das Thema Sicherheit spielt eine große Rolle. Wir bieten seit vielen Jahren Steuerungen mit integrierten Sicherheitsfunktionen und hoher Verfügbarkeit an. In den letzten Jahren hat sich die Nachfrage nach Steuerungen mit integrierten Sicherheitsfunktionen weiter verstärkt und das Marktwachstum ist signifikant höher als bei Standardsteuerungen.
Lucian Dold (Omron): Ein wesentlicher Grund für den Ansatz von ‚KI auf der Maschine für die Maschine‘ von Omron liegt auf der Hand: die Reduktion der Komplexität und die damit verbundene schnelle Umsetzung von Nutzen durch KI. Unser Ansatz favorisiert die Verbindung von effizienten Produktionsmethoden mit den Vorteilen von digitalisierter Hochautomatisierung. Ein nicht optimierter Produktionsprozess wird durch KI nicht besser. KI weitet den Flaschenhals einer schlanken und optimierten Produktion. Wichtig ist aus unserer Sicht die Unterscheidung zwischen ‚Edge‘ im Sinne von Linien- oder Fabrikintelligenz und Maschinenintelligenz, was eher dem ‚Fog‘ entspricht, oder einem ‚Drop‘, der als Beispiel der Granularität betrachtet werden kann. Security ist dabei nur ein Element, das Fog- oder Drop-Ansätze interessant macht, denn das System bleibt gekapselt und beherrschbar.
Stefan Eberhardt (Kontron/S&T): Zunächst ist es wichtig zu unterscheiden: KI, Edge und Cloud sind drei Themen, die jeweils für sich betrachtet werden müssen, um dann zu entscheiden, wie bzw. ob eine Kombination sinnvoll ist. Viele Fragestellungen sind so komplex, dass sie mit traditionellen Wenn-Dann-Logiken in Software nicht abbildbar sind (wie die Frage ‚ist mein Produkt beschädigt worden?‘). Genau hier sind KI-Algorithmen die Lösung: Sie können damit an der Maschine helfen, Fehler zu erkennen, die etwa in der Produktion auftreten. KI-Algorithmen benötigen aber enorme Rechenleistung, um zügig zu Ergebnissen zu kommen. Werden die Ergebnisse schnell vor Ort an der Maschine gebraucht, etwa um in die Steuerung nahezu in Echtzeit eingreifen zu können, ist zusätzliche Rechenleistung, beispielsweise in Form eines FPGA auf einem Edge-Device, also Steuerungsrechner, unabdingbar. Die Cloud wiederum wird benötigt, um den KI-Algorithmus zu trainieren. Er muss angelernt werden, und dafür ist die Rechen- und Speicherpower der Cloud notwendig. Wenn der Algorithmus ausgelernt hat, kann er z.B. auf den FPGA auf dem Edge-Device übertragen werden, um dort seine Aufgaben zu erfüllen. IoT-Infrastrukturen helfen, das Update von Edge-Devices zu vereinfachen. Das Thema Cloud-Sicherheit muss gesondert betrachtet werden. Hier gibt es Vorkehrungen, die die Nutzung sicher machen: von der End-to-End-Verschlüsselung der Datenübertragung bis hin zur Zwei-Faktor-Authentifizierung für Nutzer, egal ob Menschen oder Geräte. Es wird aber immer Daten und Anwendungen geben, die aus verschiedenen Gründen nicht in die Public Cloud sollen oder dürfen – hier gibt es Alternativen wie eine Private Cloud oder eine Embedded Cloud On-Premise. Ganz ohne zentrale Server oder ein Rechenzentrum wird es in der heutigen Zeit nicht mehr gehen.
Dr. Jens Frieben (Phoenix Contact Software): Ein wichtiger Grund für die Integration auf einer Steuerung ist eine lokale Optimierung, die nicht von externen Daten oder von Big Data abhängig sein muss. Hier ist es vor allem wichtig, Latenzen zu verringern und Datenverkehr über mehrere Systemgrenzen zu vermeiden. Die Daten für KI-Entscheidungen kommen direkt von der Steuerung und belasten nicht die Infrastruktur einer Anlage – dedizierte Verbindungen können eingespart werden. Zusätzlich kann auf eine Verbindung in die Cloud, die nicht immer möglich oder erwünscht ist, verzichtet werden. Neben dem Versenden von Daten durch eventuell unsichere Netzwerke soll auch der Manipulationsschutz berücksichtigt werden – eine Optimierung auf einer falschen Datenbasis kann zu kritischen und schwer identifizierbaren Fehlern führen.
Heinz-Peter Hauptmanns (Schneider Electric): KI-Algorithmen in lokalen Anwendungen haben den Vorteil zugeschnittener Lösungen, die nur die jeweiligen Aufgaben erfüllen und damit effektiver sind. Ich sehe das weniger bei Steuerungen, da sie für die Echtzeitverarbeitung zuständig sind und den Prozess bzw. die Maschine zuverlässig steuern müssen. Das Edge-Device z.B. ulPC ist ideal dafür, zumal die Baugröße und Kosten weiter fallen, als Beispiel Box-PC oder Raspberry Pi oder Arduino. Cyber Security ist und bleibt ein zentrales Thema, was sich nicht nur in den Medien darstellt, sondern sich besonders bei der Kritischen Infrastruktur Kritis zeigt und in den Normen z.B. IEC62443 und den Zertifizierungen wie beispielsweise ISO2700x darstellt. Dabei ist die lokale Lösung nicht sicherer als die Cloud, wenn Cyber Security in ihrer Umsetzung vernachlässigt wird.
Dr. Josef Papenfort (Beckhoff): In welchen Bereichen KI-Algorithmen ausgeführt werden, hängt im Wesentlichen von der vertretbaren Latenz und den maximal zulässigen Kosten ab. Ein KI-Algorithmus lebt von Daten. Zu unterscheiden sind hier zum einen die Daten, die beim Trainingsprozess (einmalig) benötigt werden, und zum anderen die Daten, die kontinuierlich bei der Prädiktion mit einem gelernten Netz (Inferenz-Betrieb) benötigt werden. Sollen Lernen und Inferenz in einer Cloud ausgeführt werden, müssen entsprechend hohe Datenraten zur Verfügung stehen. Bei Cloud-basierten Systemen kann dies dann zu hohen Kosten und möglicherweise zu Einschränkungen in der Funktionalität aufgrund zu geringer Bandbreite der Internetverbindung führen. Die Inferenz auf einem Edge-Device erfordert einen einmaligen Invest in die Hardware, kann dann aber in einem lokalen Netzwerk mit hohen Datenraten kommunizieren. Der Lernvorgang hingegen kann sinnvoll auch auf Cloud-Systemen ausgeführt werden. Das Lernen muss nicht kontinuierlich erfolgen, sodass ein einmaliger Upload von Daten genügt. Der Lernprozess erfordert aber ggf. große Rechenressourcen, welche nur temporär benötigt werden. Dafür ist das Pay-as-you-go-Bezahlmodell in einer Cloud passend.
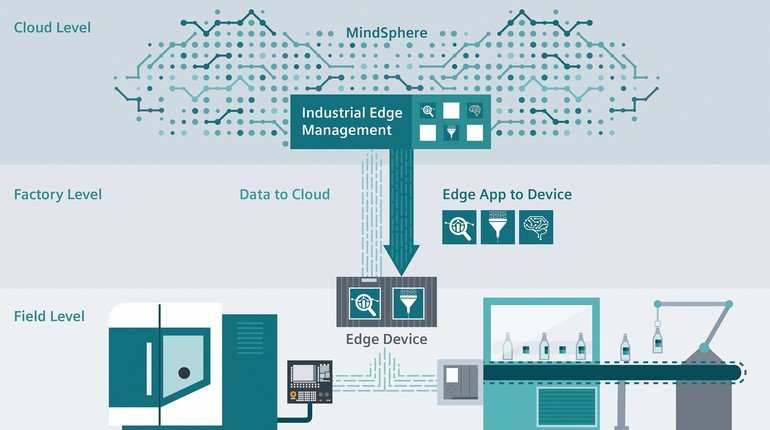
Michal Skubacz (Siemens): KI wird zunehmend für Aufgaben verwendet, die in der Vergangenheit dem Menschen vorbehalten waren. Derartige Aufgaben erfordern höhere kognitive Fähigkeiten und die Fähigkeit, komplexes Wissen situationsbedingt anzuwenden. Im Bereich der Automatisierung versprechen wir uns, KI-Algorithmen für Aufgaben einzusetzen, die weit über einfache repetitive Aufgaben hinausgehen. Aber noch ist das Zukunftsmusik, denn die komplexen Aufgaben, die wir erhoffen, mit KI in Zukunft adressieren zu können, benötigen enge Interaktion mit der Umwelt. Das bedeutet: 1. Sensoren liefern uns eine große Menge an Daten, die häufig nur von kurzer Relevanz sind und aufgrund von Datensicherheitsbestimmungen nicht gespeichert werden dürfen. 2. Geringe Latenz in Bezug auf Informationen, die an das KI-System übermittelt werden und in Bezug auf Entscheidungen, die anhand der Informationen getroffen werden. 3. Einbettung des KI-Systems in einen lokalen Kontext, im Sinne einer Spezialisierung für eine ganz bestimmte Situation. All das spricht für eine Integration von KI in lokale Applikationen, idealerweise in ein Steuerungs- und Automatisierungssystem. Da KI-Systeme dazu beitragen können, komplexe Aufgaben zu automatisieren, sollten sie als natürliche Erweiterung von Steuerungs- und Automatisierungssystemen integriert werden. So kann man von beiden Systemen profitieren: Das Steuerungssystem kann schnell auf repetitive Aktivitäten mit perfekter Automatisierung reagieren, während das KI-System auf komplexere Situationen mit geringerer Vorhersagbarkeit reagiert. Ein Steuerungssystem, das lokal in ein KI-System integriert ist, ist unabhängig von der Verfügbarkeit einer Cloud-Konnektivität. Edge-Geräte, die in ein Steuerungssystem eingebunden sind, lokal arbeiten und über eine Cloud verwaltet werden, eignen sich am besten für KI-Algorithmen. Sie bieten eine Plattform für den lokalen Betrieb von KI-Algorithmen, die eng mit dem lokalen Steuerungssystem interagieren. Das ermöglicht die Auswertung von hochfrequenten Daten, schützt Daten, die niemals ein lokales System verlassen und bietet Unabhängigkeit von konstanter Netzwerkverbindung. Gleichzeitig sind Edge-Geräte perfekt geeignet für regelmäßige Updates und Verbesserungen von Algorithmen oder Muster, die kontinuierlich auf Anforderungen verbessert und adaptiert werden.
Thomas Lantermann (Mitsubishi Electric): KI-Algorithmen können die Produktionsprozesse auf allen Ebenen verbessern. Aber da viele Entscheidungen in der Produktion in Echtzeit erfolgen müssen, bietet sich der Edge-Level an, um weitere kostenintensivere Bearbeitungen verhindern zu können. Am Beispiel einer vorbeugenden Wartung für ein Roboter-Getriebe wird dies deutlich. Die sich in Millisekunden ändernden Belastungswerte lassen sich durch die Ab-
tastraten einer Cloud nicht verlässlich analysieren. Das bedeutet, dass KI-Algorithmen so skalierbar und leistungsfähig sein müssen, dass sie problemlos in Embedded-Systeme integriert werden können. Ein weiteres Thema sind die teils ungeklärten Dateneigentumsbedingungen beim Transport und der Nutzung in der Cloud. Grundsätzlich ist es erst einmal sicherer, die Daten im Umfeld der eigenen Produktion zu analysieren und zu bearbeiten. Durch die in sich geschlossenen Produktionsnetzwerke ist eine Sicherheitskontrolle deutlich einfacher. Weiterer Vorteil des Edge-Levels sind die reduzierten Kosten für Cloud Systeme.
elektro AUTOMATION: Während Steuerungsaufgaben meist in harter Echtzeit ablaufen, erfordern KI-Algorithmen nicht zwingend Echtzeit – wie lassen sich diese beiden Anforderungen lokal verbinden?
Ashouriha: Echtzeitanforderungen und die Umsetzung der Datenverarbeitung sind wesentliche Merkmale eines ganzheitlichen Lösungsansatzes. Sensoren erkennen Abweichungen, die sich mit komplexen Analyse- und Simulationsprogramme in Echtzeit auswerten, visualisieren und in verfahrenstechnische Zusammenhänge bringen lassen. Auf Basis dieser Informationen können Maschinen- und Anlagenführer zielgerichtet die Anlagenfahrweise optimieren und Programmänderungen vornehmen.
Dold: Der Begriff von Echtzeit ist unserer Auflassung nach immer relativ zum Prozess zu betrachten. Wir sehen vielmehr den Unterschied in der Strenge der Deterministik. Während die Maschinensteuerung genau der Sequenz und Logik zu folgen hat, wird die KI-Engine lernen und sich adaptieren. Damit ändert sich folglich deren Zeitverhalten innerhalb zu definierender Grenzen. Der Nutzen einer maschinennahen KI ist die autonome Optimierung von Parametern und/oder die Erkennung von Anomalien innerhalb eines Zeitintervalls, um angemessen zu reagieren. Da KI bei der Sysmac mit auf der technologischen Plattform implementiert und in der Leistungsfähigkeit frei skalierbar ist, kann je nach den Prozessanforderungen die KI im Sinne des Prozesses auch in Echtzeit optimieren.
Eberhardt: Wichtig ist, dass die OT-Seite, die Echtzeitsteuerung, unbeeinflusst bleibt von den Aktualisierungen, die in der IT-Welt die Regel sind. Die korrekte Steuerung der Maschine darf auf keinen Fall gefährdet werden. Es bestünde die Gefahr, dass das Laufzeitverhalten beeinträchtigt würde, was wiederum in einer Produktionsstraße unabsehbare Folgen für vor- und nachgelagerte Systeme hätte. Zudem ist die Steuerung der Maschinen und all ihrer Komponenten zertifiziert; bei Eingriffen in die Steuerung wäre eine Re-Zertifizierung mit jedem Update notwendig, was in der Praxis nicht umsetzbar ist. Um trotzdem Informationen aus der IT-Welt zu verarbeiten und IoT damit einsetzbar zu machen, setzt S&T, der Mutterkonzern von Kontron, schon lange auf das Prinzip des Hypervisors. Er trennt zwischen IT und OT auf ein und derselben Hardware. Neueste Entwicklungen der IT-Seite können damit integriert werden – nicht nur KI, sondern auch Big Data und andere IoT-Technologien, ohne den Betrieb der Maschine zu gefährden. Damit lassen sich beispielsweise auch Anwendungen integrierten, die in der Cloud betrieben werden, etwa Services wie sie Microsoft mit Azure IoT Edge anbietet. Das ist auch der Grund, warum mittlerweile Hardware von Kontron Microsoft-Azure-zertifiziert wird.
Frieben: Moderne Steuerungen – wie die AXC F 2152 – bieten die Möglichkeit, Real-Time- und Non-Real-Time-Anwendungen parallel auszuführen. Gerade beim Einsatz mehrerer Prozessorkerne können Entwickler flexibler auf Anforderungen reagieren und Ressourcen optimal nutzen. Dies ist insbesondere wichtig, wenn KI-Algorithmen auf wenigen, jedoch konstanten Datenströmen arbeiten. Oft reicht ein kleines Fenster in die Vergangenheit, um Entscheidungen zu fällen und die Steuerungsaufgaben der Echtzeit anzupassen. Eine notwendige Voraussetzung hierfür ist jedoch eine zuverlässige, einfache und schnelle Schnittstelle zwischen den beiden Welten, wie sie etwa von PLCnext-basierten Steuerungen angeboten wird.
Hauptmanns: Heute trennt man noch gerätetechnisch in eine SPS für die harte Echtzeit und einen Edge Controller für die KI-Algorithmen. Durch die höhere Rechenleistung ist dies in einem Gerät machbar, aber die reine Steuerungsebene bevorzugt heute noch eine Trennung der Aufgaben, um bei Ausfällen der Hardware direkt einen 1zu1-Austausch vornehmen zu können (FDR=Faulty Device Replacement).
Papenfort: Die Art der Verbindung hängt von der Applikation ab, welche durch einen KI-Algorithmus realisiert oder unterstützt werden soll. Klar ist, dass der KI-Algorithmus Daten aus dem Echtzeitprozess benötigt, also ein Datenstrom von der Echtzeit in die Nicht-Echtzeit-Welt realisiert werden muss. Im Wesentlichen muss aber dann die Frage gestellt werden, ob der Nicht-Echtzeit-Algorithmus einen Rückeingriff in den Echtzeitprozess benötigt. Darauf verzichtet werden kann beispielsweise dann, wenn der KI-Algorithmus im Bereich der prädiktiven Wartung eingesetzt wird, beispielsweise eine ‚rest of useful life‘-Prädiktion ausgeführt werden soll. Hier ist ein direkter Eingriff zurück in den Echtzeitprozess in der Regel nicht nötig. Soll hingegen eine geschlossene Optimierungsschleife realisiert werden, muss der KI-Algorithmus die Resultate wieder mit dem Echtzeitprozess austauschen.
Skubacz: KI-Algorithmen laufen normalerweise nicht in Echtzeit ab, weil dafür viel Rechenleistung benötigt wird. Hier ist aktuell ein Umbruch zu beobachten, denn es wird bereits kräftig an Hardware für KI-Systeme getüftelt, die es insbesondere ermöglichen soll, die Geschwindigkeit von KI-Systemen zu beschleunigen. Andererseits ist es wichtig zu verstehen, dass KI-Algorithmen, wie beispielsweise Deep Learning, in der Lernphase und in der Ausführungsphase/Datenevaluierungsphase unterschiedliche Rechenanforderungen haben. Letzteres benötigt deutlich weniger Rechenleistung. Hier ist die Kombination von Steuerungssystem und KI-System ein geeigneter Lösungsansatz und kann auf unterschiedliche Weise realisiert werden. Zum einen kann man das Steuerungssystem mit geeigneten Beschleunigungsmöglichkeiten für die KI-Algorithmen erweitern. Zum anderen kann man das Steuerungssystem mit einem Edge-Gerät ausstatten, was Rechenleistung und Funktionen zur Beschleunigung der Geschwindigkeit für die KI-Algorithmen liefert. Insbesondere der zweite Ansatz ist sehr gut umsetzbar und bringt eine Arbeitsteilung der Systeme mit sich. Er erlaubt dem Steuerungssystem, sich auf Echtzeitsteuerungsaufgaben zu konzentrieren, während das Edge-System Rechenleistung und Netzwerkmöglichkeiten für eine Echtzeit-KI-Applikation zur Verfügung stellt.
Lantermann: Obwohl KI nicht zwingend Echtzeit erfordert, verbessern sich die Ergebnisse bei ihrem Einsatz deutlich. Das rührt daher, dass in einer Produktionslinie schnell entschieden werden muss, ob ein Produkt den Anforderungen entspricht. Wird ein Mangel festgestellt, nachdem das Produkt bereits weitere Produktionsprozesse durchlaufen hat bzw. im schlimmsten Fall bereits verpackt worden ist, kann es zu Verlusten von ganzen Einheiten kommen. Die ideale Lösung ist ein Edge-Device, das die Echtzeitanforderungen in einem Echtzeit-Betriebssystem durchführen würde, aber auch die Flexibilität der Windows-Welt in Bezug auf Datenspeicherung und einfache Cloud-Anbindung integrieren kann. Solche Lösungen sind bereits heute im Markt verfügbar. Hier kann als zusätzlicher Vorteil durch die Trennung des Windows-Systems vom Real-Time-Produktionspart auch noch die Cyber-Sicherheit gewährleistet werden.
elektro AUTOMATION: Wann stoßen lokale KI-Anwendungen aufgrund der Rechenleistung an ihre Grenzen und welche Anwendungen sind dafür geeignet?
Ashouriha: Die Skeptiker der Digitalisierung sehen in dieser Transformation, Technologien die belächelt und für ‚Spielzeug‘ gehalten werden. Mit der Integration von KIs wird über die nächsten Jahre ein Stück Technologie den Maschinenbau revolutionieren. Speziell der Sondermaschinenbau dürfte stark davon profitieren, da KIs entscheidende Wettbewerbsvorteile bringen werden.
Dold: Wenn KI maschinennah eingesetzt wird, erfordert das mehr als einfach nur die Mechanismen von Hochleistungssystemen oder Performance aus einer Cloud heraus zu portieren. Weniger ist mehr lautet der Schlüssel zum Erfolg. Zum einen muss daher der Prozess schlank und optimiert sein. Des Weiteren ist es geboten, den Flaschenhals zu identifizieren und die verfügbaren Datenquellen am kritischen Prozess frei zu legen. Gerne zitieren wir hier die Aussage von Alan Mackworth von der University of British Columbia: ‚The data that are easy to get may not be the most informative.‘ Werden dann, wie im Falle von Sysmac, speziell für die maschinennahe Anwendung geeignete Algorithmen verwendet, optimiert und analysiert das KI-System lokal ohne zwangsweise an die Leistungsgrenzen zu geraten.
Eberhardt: Das Fundament von Edge-seitigen KI-Anwendungen sind trainierte neuronale Netze. Wenn wir beispielsweise eine Kamera mit durchschnittlicher Auflösung verwenden, um die Qualität eines Produkts zu prüfen, dann sind hier mehrere 10.000 Neuronen beteiligt, die simuliert werden müssen. Der Nutzen des KI-Einsatzes ist, dass nicht alle möglichen Arten einer Beschädigung oder möglicher Mängel vorab bekannt sein müssen. Selbstverständlich stoßen die typischen Edge-Prozessoren hier schnell an ihre Grenzen. Erfreulich ist aber, dass sich KI-Entwicklungen vergleichbar zur Blockchain-Technologie zeigen. Während vor einem Jahr noch leistungsfähige Grafikkarten verwendet wurden, um die nötige Rechenpower bereitzustellen, gibt es derzeit schon die ersten FPGA-Karten, die sich wesentlich effizienter dieser Aufgabe widmen. Diese sind auch auf Kontron-Geräten verfügbar: Die Hardware bleibt kompakt wie bisher, ist aber ‚KI-Ready‘.
Frieben: Optimierungen in Steuerungsalgorithmen – Stichwort Selbstoptimierung intelligenter technischer Systeme – oder das Aufbereiten von Rohdaten können beliebig rechenintensiv werden. In der Regel hängt die Entscheidung, ob ein Algorithmus lokal ausgeführt werden kann, von mehreren Faktoren ab. Vor allem wenn viele Datenpunkte in kurzen Zyklen aufgezeichnet, aufbereitet, ausgewertet und gespeichert werden, kommen Steuerungen schnell an ihre Leistungsgrenzen. Hier sollten High-Performance-Geräte – wie der RFC 4072S – zum Einsatz kommen. Alternativ bietet sich die Verwendung eines Edge-Devices an – etwa die Steuerung AXC F 2152. Sie erleichtert eine Trennung von Aufbereitung und Auswertung durch die Verwendung des integrierten OPC-UA-Servers oder durch die Erweiterung um eigene Kommunikationskomponenten und Protokolle.
Hauptmanns: KI-Anwendungen in SPSen beschränken sich meistens auf Predictive Control von Prozess-Schleifen, als Weiterentwicklung von PID-Schleifen, oder Datenauswertung von Geräten wie Frequenzumrichtern für Predictive Maintenance zur vorbeugenden Wartung. Dabei handelt es sich um komplexe Funktionsbausteine und keine KI-Algorithmen. Hier ist nicht unbedingt die Rechenleistung ausschlaggebend, da diese immer noch gesteigert wird, sondern der Wunsch, die Edge-Control-Ebene zur Datenvorverarbeitung/-konzentration zu nutzen. KI-Anwendungen finden in der darüber liegenden Ebene, beispielsweise in unserem IIoT-System EcoStruxure statt. Die Apps mit KI-Algorithmen werden sowohl lokal als auch in der Cloud genutzt. Beispiele bei Schneider Electric sind Apps wie Asset Advisor, Resource Advisor oder Profit Advisor, die sowohl die Produktion als auch das gesamte Geschäft betrachten.
Papenfort: Diese Frage kann kaum zielführend beantwortet werden. Es hängt von der verwendeten Hardware ab, ob ein Edge-De-vice die Rechenleistung mitbringt, ein bestimmtes Deep Neural Network in geeigneter Zeit zu berechnen. In PC-basierten Steuerungssystemen kann die Hardware bedarfsgerecht skaliert werden.
Skubacz: Die Gründe dafür reichen von einer falsch designten Architektur über natürliche Grenzen der Hardware bis hin zu einer ungeeigneten Hardwarearchitektur. Viele KI-Anwendungen laufen wunderbar parallel auf geeigneten KI-Rechenbeschleunigern von Grafikprozessoren, während ein Hauptprozessor für eine solche Anwendung in der Regel ungeeignet ist. Beispielsweise können Bilderkennungsaufgaben, die tiefe neuronale Netzwerke nutzen, effizient auf einer integrierten Hardware – zum Beispiel einem Edge-Gerät – laufen. Allerdings müssen die meisten Daten-getriebenen KI-Ansätze erstmal KI-Muster, wie tiefe neuronale Netzwerke, erlernen. Dieser Lernprozess kann in der Regel nicht auf lokaler Hardware mit limitierter Rechenleistung erfolgen. Dafür ist eine Cloud-Lösung besser geeignet. Ideal ist also eine Mischung aus einem lokalen Edge-System, worüber bereits erlernte KI-Muster ausgeführt werden, und einem angeschlossenem Cloud-System, über das das Erlernen der KI-Muster erfolgen kann und das somit das Edge-System unterstützt.
Lantermann: Eine typische Anwendung für KI ist die automatische Wave-Form-Erkennung (Kurvenverlauf). Für die Qualität eines Produktes oder Prozesses sind häufig Temperatur-, Moment-, Stromverläufe usw. wichtig. Meistens ist es ein Zusammenspiel von mehreren Komponenten. Mit einer Multiple-Wave-Form-Analyse können hier in Echtzeit Entscheidungen gefällt werden. Durch die Möglichkeit, mit einfachen Werkzeugen offline ein mathematisches Modell zu erstellen und dies dann in der Produktion zu benutzen, kann die lokale Rechenleistung den Echtzeit Erfordernissen und den Edge-Geräten anpasst werden. Big-Data-Analysen sind weder für den Office-PC noch für die Steuerungen in der Produktion geeignet. Um diese Möglichkeiten sinnvoll zu nutzen, ist die einfache Anbindung an Cloud-Systeme erforderlich.
elektro AUTOMATION: Gibt es aus Ihrer Sicht auch Anwendungsszenarien, die sich nur in der Cloud sinnvoll abbilden lassen; beispielsweise standortübergreifende Analysen?
Ashouriha: Heute können Kunden moderne Technologien wie Cloud- und Analyseplattformen nutzen, um ihr Unternehmen im Rahmen von Industrie 4.0 digital zu transformieren. Moderne Ansätze für Prozessleitsysteme (DCS), Fertigungssteuerungssysteme (MES) und Analytik ermöglichen innovative Ansätze zur Produktivitätssteigerung und Erschließung neuer Märkte. Durch die Nutzung von Informationen aus dem gesamten Produktionsbereich lassen sich weitere Möglichkeiten im Rahmen der unternehmerischen Wertschöpfungskette erschließen. Seit Jahrzehnten nutzt die Branche Daten, um Kosten zu senken und die Produktivität zu steigern. Der Fertigungssektor erzeugt mehr Daten als jeder andere.
Dold: Die Leistungsfülle einer Cloud bietet in jedem Fall für die Anwendung eine Bühne, die mit einem hohen Aufkommen von überbestimmten, teils willkürlich gesammelten Daten die ‚Nadel im Heuhaufen‘ finden muss. Dies bietet sich an, wenn Kausalitäten nicht beschrieben sind oder mit vertretbarem Aufwand zu beschreiben sind. Die Cloud ist aber auch der ideale Partner für Drop, Fog und Edge, die eine kaskadierte Intelligenz nutzen. Erkannte Anomalien oder lokale Lernsätze können mit einer übergeordneten Cloud in der Tiefe analysiert werden und die Parameter der lokalen KI optimieren.
Eberhardt: Auswertungen und Analysen sind generell ein typisches Cloud-Thema, da sie üblicherweise keine 100-prozentige Verfügbarkeit und keine Echtzeitfähigkeit benötigen. Außerdem machen es Cloud-gestützte Systeme leichter, Daten aus verschiedenen physischen Orten zu konsolidieren. Ergänzend bietet die Cloud praktisch unbegrenzt Speicherplatz, etwa um auf historische Daten zuzugreifen. Um beim Thema KI zu bleiben: Wenn wir ein neuronales Netz trainieren, so erfordert dies hohe Rechenleistung, denn es müssen sehr viele Neuronen simuliert werden. Wenn wir beispielsweise die Frage klären wollen, ob auf einem bestimmten Bild eine Katze oder ein Hund zu sehen ist, so benötigen wir etwa 25.000 Bilder. Dieses Beispiel zeigt deutlich: Zum Trainieren wird sehr große Rechenleistung benötigt. Dies lässt sich am wirtschaftlichsten in der Cloud realisieren. Abseits von KI gibt es noch viele Anwendungsfälle, die die Cloud erfordern. Viele unserer Kunden sind Hersteller von Maschinen und keine Endanwender. Im B2B-Umfeld ist beispielsweise die Bereitstellung eines Kundenportals zur Geräteverwaltung für Endkunden und Serviceorganisation ein idealtypisches Cloud-Szenario. Auf dieser Plattform können die Endkunden einerseits ihre Geräte verwalten, andererseits erhalten sie aber noch wertvolle Informationen, ob die Maschinen optimal eingesetzt werden, individuelle Wartungsinformationen oder etwaige Anknüpfungspunkte zur Prozessoptimierung.
Frieben: Für einen cloudbasierten Ansatz sprechen Datenmenge, Anzahl der involvierten Systeme, Echtzeitanforderungen und technologische Voraussetzungen. Basis für Analysen sind oft Daten, die über einen längeren Zeitraum aufgezeichnet und daher nicht auf einer Steuerung abgelegt werden können. Bezieht sich eine Optimierung gleich auf mehrere Steuerungen und Anlagen oder gar Standorte, macht eine zentrale Koordination aus der Cloud ebenfalls Sinn. Zusätzliche Dienste für komplexe Berechnungen, Wetter- oder Routeninformationen, wie sie zum Beispiel von der Proficloud bereitgestellt werden, sind gute Gründe für eine Applikationslogik, die von der Steuerung in die Cloud zieht.
Hauptmanns: Sobald Daten standortübergreifend genutzt werden, ist eine übergreifende Verarbeitung zwingend notwendig. Ob diese an einem oder mehreren Orten, im eigenen Rechenzentrum oder Cloudsystem stattfindet, ist dabei unwesentlich. Das Entscheidende sind die Infrastrukturkosten (Hardware, Software, Wartung, Systemspezialisten, …), die man bei einem lokalen System komplett selbst trägt, aber bei einem Cloud-System monatlich abschreiben kann. In puncto Cyber Security ist die Cloud sogar von Vorteil, weil die lokale Umsetzung häufig große Lücken aufweist.
Papenfort: Auch hier ist die Auftrennung in Lernphase und Inferenz zu betrachten. Das Lernen basiert auf einer Sammlung von Daten. Wird an einem einzelnen Standort nicht genügend Datenvolumen erzeugt, so kann das Koppeln mehrerer Standorte helfen, die den gleichen Prozess abbilden. Dazu ist die Cloud ein geeignetes Bindemittel. Zudem stellt sie die Rechenleistung zur Verfügung, um zu einem bestimmten Zeitpunkt den Lernvorgang in Gang zu setzen. Ob die Inferenz dann auch in der Cloud stattfinden soll, hängt von der konkreten Applikation, der Latenz und der Datenrate ab.
Skubacz: Eine Cloud-Lösung passt am besten zu Anwendungen, die entweder eine hohe Rechenleistung benötigen oder bei denen Informationen zwischen Maschinen oder gar Standorten ausgetauscht werden müssen. Das zentrale Aufbewahren von Informationen erlaubt es, zu lernen und Rückschlüsse aus Erfahrungen und Situationen, die in verschiedenen Standorten passiert sind, zu ziehen. Das verbessert die Qualität der Ergebnisse sowie ihre Verlässlichkeit. Eine Fertigung an einem bestimmten Standort schafft es beispielsweise, Qualitätsprobleme zu überwinden, die aufgrund hoher Umgebungstemperaturen entstanden sind. Das daraus Gelernte könnte man auf eine andere Fertigung an einem anderen Standort übertragen, auch wenn dort hohe Temperaturen nur ab und zu möglich sind. Generell haben sowohl lokale als auch zentrale Anwendungen ihre Berechtigung, denn es hängt immer von den jeweiligen Anforderungen und Gegebenheiten ab. Eine Kombination aus Edge Computing, das über eine Cloud verwaltet wird, und Cloud Computing sowie einer integrierten Infrastruktur ist deshalb eine Lösung, um den Anforderungen in der Fertigung gerecht zu werden.
Lantermann: Zu den Szenarien zählen beispielsweise Big-Data-Analysen, die über Cloud-Systeme abgebildet werden und mit deren Hilfe sich Produktionsstätten standortübergreifend optimieren lassen. Die Optimierung von industriellen und Konsumgütern erfolgt durch die Datenerfassung direkt beim Endkunden, die die Daten dann in die Cloud zur Analyse schicken. Die so gewonnenen Erkenntnisse helfen bei der Verbesserung der Produktionsschritte. Auch sind Cloud-Daten für die kundenorientierte Neuentwicklung von Produkten mehr als hilfreich. So könnte als Beispiel die Motorleistung und die Reichweite eines Roboters besser an die Kundenbedürfnisse angepasst werden, wenn die Entwicklungsabteilungen Zugriff auf die Nutzungsdaten der Endkunden bekommen. Wichtig ist immer, dass es bei der Auswertung der Daten eine Win-Win-Situation für den Verbraucher und den Produzenten gibt. Dies kann nur erreicht werden, wenn die Daten sicher und verantwortungsbewusst genutzt werden. Dann kann KI zum Erfolg auf allen Ebenen der Wertschöpfungskette beitragen.
www.beckhoff.de; Messe Motek: Halle 8, Stand 8108
www.phoenixcontact.de; Messe Motek: Halle 7, Stand 7525
www.siemens.com; Messe Motek: Halle 8, Stand 8102
„Sensoren erkennen Abweichungen, die sich mit komplexen Analyse- und Simulationsprogrammen in Echtzeit auswerten, visualisieren und in verfahrenstechnische Zusammenhänge bringen lassen.“
 Ashkan Ashouriha, Solution Architect Integrated Architecture & Connected Enterprise bei Rockwell Automation in Düsseldorf
Ashkan Ashouriha, Solution Architect Integrated Architecture & Connected Enterprise bei Rockwell Automation in DüsseldorfBild: Rockwell Automation
„Ein nicht optimierter Produktionsprozess wird durch KI nicht besser, KI weitet jedoch den Flaschenhals einer schlanken und optimierten Produktion.“
 Lucian Dold, General Manager Marketing Product and Solution EMEA bei Omron in Langenfeld
Lucian Dold, General Manager Marketing Product and Solution EMEA bei Omron in LangenfeldBild: Omron
„KI-Algorithmen können an der Maschine helfen, Fehler zu erkennen, sie benötigen aber enorme Rechenleistung, um zügig zu Ergebnissen zu kommen.“
 Stefan Eberhardt, Business Development Manager bei S&T Technologies in Augsburg
Stefan Eberhardt, Business Development Manager bei S&T Technologies in AugsburgBild: S&T
„Gerade beim Einsatz mehrerer Prozessorkerne bieten moderne Steuerungen die Möglichkeit, Real-Time- und Non-Real-Time-Anwendungen parallel auszuführen.“
 Dr. Jens Frieben, Director PLCnext Runtime Platform bei Phoenix Contact Software in Lemgo
Dr. Jens Frieben, Director PLCnext Runtime Platform bei Phoenix Contact Software in LemgoBild: Phoenix Contact
„KI-Algorithmen auf dem Edge-Device in lokalen Anwendungen haben den Vorteil zugeschnittener Lösungen, die nur die jeweiligen Aufgaben erfüllen und damit effektiver sind.“
 Heinz-Peter Hauptmanns, Produktmanager Automatisierung im Bereich Industrie bei Schneider Electric in Düsseldorf
Heinz-Peter Hauptmanns, Produktmanager Automatisierung im Bereich Industrie bei Schneider Electric in DüsseldorfBild: Schneider Electric
„Da der Lernprozess ggf. große Rechenressourcen erfordert, die nur temporär benötigt werden, ist dafür das Pay-as-you-go-Bezahlmodell in einer Cloud passend.“
 Dr. Josef Papenfort, Produktmanager Twincat bei Beckhoff Automation in Verl
Dr. Josef Papenfort, Produktmanager Twincat bei Beckhoff Automation in VerlBild: Beckhoff Automation
„Eine Cloud-Lösung passt am besten zu Anwendungen, die entweder eine hohe Rechenleistung benötigen oder bei denen Informationen zwischen Maschinen oder gar Standorten ausgetauscht werden müssen.“
 Michal Skubacz, Leiter Industriesoftware Motion Control bei der Siemens AG in Nürnberg
Michal Skubacz, Leiter Industriesoftware Motion Control bei der Siemens AG in NürnbergBild: Siemens
„Mit Big-Data-Analysen, die über Cloud-Systeme abgebildet werden, lassen sich Produktionsstätten standortübergreifend optimieren.“
 Thomas Lantermann, Senior Business Development Manager bei Mitsubishi Electric in Düsseldorf
Thomas Lantermann, Senior Business Development Manager bei Mitsubishi Electric in DüsseldorfBild: Mitsubishi Electric




{kind=link}