Inhaltsverzeichnis
1. Was sind die Vorteile einer Hardwareimplementierung?
2. Verwendung des Zynq-SOCs in einem Embedded System
3. Zu dieser Serie
Die Fortschritte der Halbleitertechnik ermöglichen es heute bei Strukturgrößen von 7 nm mehrere Milliarden von Transistoren auf einem Chip zu integrieren. Dies wiederum führt zur Entwicklung komplexer Prozessorsysteme, einem sogenannten System-On-Chip (SOC), das beispielsweise in Smartphones Verwendung findet. Der Kirin 970-SOC von Huawei integriert beispielsweise vier ARM Cortex-A73 und vier Cortex-A53 64-Bit-Prozessorkerne, eine Graphics Processing Unit (GPU) sowie eine Neural Processing Unit (NPU) und benötigt hierzu etwa 5,5 Milliarden Transistoren auf einer Chipfläche von rund 100 mm2. Als Embedded System wird ein Prozessorsystem bezeichnet, wenn es für den Anwender nicht als solches erkennbar ist und in ein technisches System, wie beispielsweise eine Kaffeemaschine oder ein Kraftfahrzeug, eingebettet ist. Hier werden häufig keine Hochleistungs-SOCs benötigt, sondern dies ist die Domäne von preisgünstigen sogenannten Mikrocontrollern, bei denen etwas einfachere Prozessoren mit Speicher und Peripherieeinheiten auf einem Chip integriert werden. Auch bei den Mikrocontrollern werden sehr häufig Prozessorkerne des Unternehmens ARM verwendet, in der Regel die einfacheren 32-Bit Prozessorkerne der Cortex-M-Serie. Gemeinsam ist diesen Systemen, dass der Anwender dieser Chips die Funktionalität des Systems über die darauf ausgeführte Software definiert, die (digitale) Hardware der Chips ist nicht veränderbar.
Im Gegensatz dazu kann bei programmierbaren Logik-Bausteinen, dem sogenannten Programmable Logic Device (PLD) die digitale Hardware in ihrer Funktion verändert werden. Für die Integration von komplexen Systemen sind insbesondere Field-Programmable Gate-Arrays (FPGAs) geeignet. Den größten Anteil stellen hier SRAM-FPGAs dar, bei denen die Programmierbarkeit durch SRAM-Zellen implementiert wird. Die Unternehmen Altera/Intel und Xilinx sind die beiden großen Anbieter von SRAM-FPGAs. Mit FPGAs wird es möglich, Algorithmen, die auf einem Prozessorsystem in Software implementiert werden, direkt in der programmierbaren Hardware zu implementieren.
Was sind die Vorteile einer Hardwareimplementierung?
Die Software wird auf einem Mikroprozessor durch die Maschinenbefehle sequentiell abgearbeitet. Performance-Steigerungen sind durch höhere Taktfrequenzen, superskalare Prozessorarchitekturen und die Verwendung mehrerer Prozessorkerne möglich – dies alles wird in modernen SOCs auch ausgenutzt. Bei einer Implementierung der Algorithmen in Hardware kann allerdings sehr viel stärker parallelisiert werden und damit auch eine deutlich höhere Performance erreicht werden. Gerade für Signalverarbeitungsalgorithmen sind FPGAs sehr gut geeignet: Ein Xilinx Virtex UltraScale+ FPGA verfügt beispielsweise über knapp 10.000 DSP-Cores, die jeweils eine sogenannte Multiply-Accumulate-Operation durchführen können, so dass es beispielsweise möglich wird, digitale Filter vollständig parallel zu implementieren. Insbesondere auch die Bildverarbeitung profitiert von der Möglichkeit, die Algorithmen stärker parallelisiert in Hardware implementieren zu können.
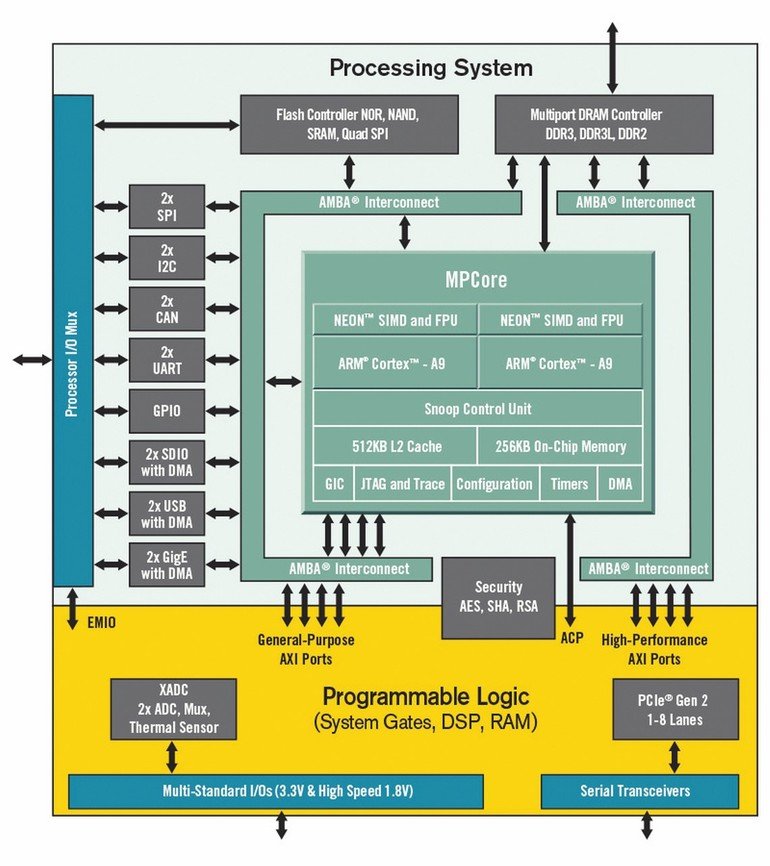
Hybride CPU-FPGA-Chips vereinen Prozessorsysteme und programmierbare Logik auf einem Chip. Ein Beispiel hierfür ist der in Abbildung 1 gezeigte Zynq-FPGA der Firma Xilinx. Der Zynq-SOC besteht aus zwei Teilen: Das sogenannte Processing System (PS) beinhaltet zwei Cortex-A9 Prozesssorkerne mit jeweils einem Level1-Cache und einem gemeinsamen Level2-Cache. Über ein Bussystem sind Peripherieeinheiten von SPI und IIC bis hin zu USB und Gigabit-Ethernet verfügbar. Ferner ist noch ein Flash- und ein DRAM-Controller mit integriert. Die Programmable Logic (PL) stellt den programmierbaren FPGA-Teil des SOCs dar: Je nach Zynq-Variante sind hier eine unterschiedliche Zahl von FPGA-Ressourcen vorhanden (DSP-Cores, BlockRAM, Flipflops und Look-Up-Tables). Im PL-Teil können eigene Komponenten, sogenannte IP-Cores, eingebaut werden und über die Busschnittstellen mit dem Prozessorsystem verbunden werden. Für die Implementierung der IP-Cores hat der Anwender im Prinzip drei unterschiedliche Möglichkeiten: Man kann aus der Xilinx-Bibliothek einen IP-Core auswählen oder man entwickelt selbst einen IP-Core mit einer Hardwarebeschreibungssprache wie VHDL oder Verilog. Die dritte Möglichkeit besteht in der direkten Umsetzung von Software-Funktionen, die man als C/C++-Code vorliegen hat, in einen Hardware-IP-Core. Für die letztere Möglichkeit wird ein spezielles Werkzeug, die „High-Level-Synthese” benötigt, die Teil der Xilinx-Vivado-Tool-Kette ist. Für weitere Informationen zur Entwicklung von IP-Cores mit VHDL oder mit C/C++ sei beispielsweise auf verwiesen.
Verwendung des Zynq-SOCs in einem Embedded System
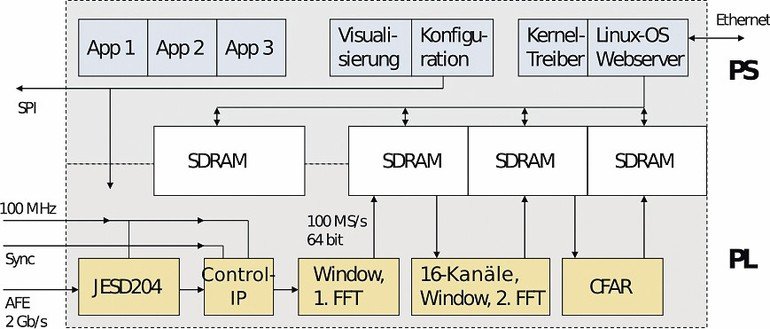
Abschließend sei noch ein Beispiel für die Verwendung des Zynq-SOCs in einem Embedded System beschrieben: An der Hochschule Pforzheim wurde im Rahmen eines Forschungsprojektes ein Embedded System für die Detektion von RADAR-Signalen entwickelt. Neben dem 160 GHz HF-Frontend und den zugehörigen analogen Systemteilen ist das Kernstück des Systems das Zynq-SOC. Das RADAR-Sensorsystem arbeitet nach dem sogenannten Chirp-Sequence-Verfahren und ist in der Lage, den Abstand und die Geschwindigkeit von Objekten zu bestimmen. Hierzu werden nacheinander mehrere linear frequenzmodulierte “Rampen” ausgesendet und das reflektierte Signal einer Rampe wird, von einem A/D-Wandler kommend, dem Zynq-SOC über eine JESD204-Schnittstelle zugeführt. Die Berechnung von Abstand und Geschwindigkeit erfolgt mittels einer 2D-FFT (zweidimensionale “Fast Fourier Transform”). Die erste FFT wird hierbei durch einen entsprechenden IP-Core in der programmierbaren Logik im “Streaming”-Modus über die abgetasteten Eingangssignale gerechnet und die Ergebnisse werden im SDRAM-Hauptspeicher des Systems zwischen gespeichert. Die zweite FFT wird ebenfalls durch einen IP-Core in der PL implementiert. Hierbei werden allerdings 16 Kanäle und damit 16 FFTs parallel gerechnet, um einen höheren Durchsatz zu erreichen. Die Ergebnisse der zweiten FFT werden ebenfalls wieder im SDRAM gespeichert. Somit liegen nun die Rohdaten der 2D-FFT vor und können durch nachfolgende Verfahren zur Objekterkennung verwendet werden, wie beispielsweise das CFAR-Verfahren, das auch wieder durch einen IP-Core in der PL implementiert werden kann. Für ein Beispiel von 64 Rampen und 4096 Samples pro Rampe konnte eine Rechenzeit für die 2D-FFT von rund 9 ms erreicht werden.
Die Berechnung einer 2D-FFT in der gleichen Konfiguration (64 x 4096) auf einem leistungsfähigen PC (3,6 GHz I7-Quad-Core-Prozessor) mit Matlab benötigt rund 5 ms. Daraus wird ersichtlich, dass man auch in kleinen Embedded Systems durch den Einsatz von hybriden CPU-FPGA-SOCs und der Auslagerung von rechenintensiven Teilen der Anwendung in die Hardware Rechenleistungen erzielen kann, für die anderenfalls leistungsfähige PCs notwendig wären. Darüber hinaus bietet das verwendete Zynq-SOC den Vorteil, dass ein Embedded Linux OS darauf läuft, so dass weitere Software-Anwendungen, wie beispielsweise ein Webserver für die Visualisierung der Ergebnisse, problemlos implementiert werden können. eve
Info
Details werden in Seminaren der Technischen Akademie Esslingen (TAE) vorgestellt. Näheres und Anmeldung unter:
Embedded System Design 18.03.2019 – 19.03.2019
Digitales Hardwaredesign mit VHDL und FPGAs
20.02.2019 – 22.02.2019
FPGA-Design mit C/C++ und High-Level Synthese 21.10.2019 – 22.10.2019

info
Zu dieser Serie
Zusammen mit der Technischen Akademie Esslingen e.V. stellt die elektro AUTOMATION in dieser Grundlagenserie Hintergründe und praktische Einsatzszenarien in aktuellen Technikfeldern zusammen. Tipps zu passenden Seminarangeboten erleichtern die Planung einer praxisorientierten Weiterbildung.




{kind=link}