Mit Industrial AutoML stellt Weidmüller ein Tool zur Verfügung, das den Prozess des Machine Learnings vereinfachen und den Ingenieuren in der Automatisierung das Erstellen von Modellen erleichtern soll. Wie das Arbeiten mit Industrial AutoML in der Praxis erfolgt und was beim Einsatz von Machine-Learning zu beachten ist, erläutert Dr. Carlos Paiz Gatica, Produktmanager im Bereich Industrial Analytics bei Weidmüller.
Andreas Gees, stv. Chefredakteur elektro Automation
Da in der Industrie kaum ausreichend Datenspezialisten verfügbar sind, müssen die Automatisierer bzw. Domäne-Experten befähigt werden, mit dieser Technologie zu arbeiten. Das ist die Vision hinter Industrial AutoML. Ziel der Entwicklung von Weidmüller GTI ist es deshalb, die Automatisierer zu befähigen, Projekte zu bearbeiten, ohne auf Datenspezialisten angewiesen zu sein. Mit AutoML wurde der Prozess automatisiert und in einer Software abgebildet.
Aufgabe eines Domäne-Experten ist es, ein Ziel zu definieren, Daten auszuwählen, zu importieren und in einen Kontext zu bringen. Er muss definieren, ob eine Maschine im normalen Betriebszustand läuft oder ob ein Problem aufgetreten ist. Er muss auch entscheiden, welche Sensordaten für die Betriebszustände aussagefähig sind. Das AutoML-Tool übernimmt die weiteren Aufgaben und erzeugt am Ende des Prozesses eine Reihe von Modellen, die der Automatisierungs- oder Prozessexperte im Einzelnen bewerten muss.
Industrial AutoML ist bereits in verschiedenen Anwendungen im Einsatz. Die Erfahrungen aus diesen Projekten fließen in die Weiterentwicklung des Tools ein. Industrial AutoML basiert auf Open-Source-Technologien und nutzt gängige Open-Source-Libraries, wobei vor allem die typischen in der Industrie erzeugten Daten im Vordergrund stehen.
ModelBuilder und ModelRuntime
Industrial AutoML besteht aus zwei Modulen. Der ModelBuilder läuft in der Cloud, die die erforderliche Flexibilität zur Verfügung stellt, um auch rechenintensive Prozesse zu unterstützen. Der Nutzer kann entscheiden, ob er die Runtime in der Cloud oder On Premise in der Produktion nutzen möchte, denn oft dürfen Daten eine Anlage nicht verlassen.
Beim Start des ModelBuilders erscheinen mit den Datasets und den Projects zwei Elemente auf dem Dashboard. Aufgabe des Nutzers zu Beginn eines Prozesses ist es, die Sensordaten aus der Maschine zu importieren und ihnen zeitliche Informationen zuordnen. Die Daten lassen sich dann für unterschiedliche Projekte bzw. für unterschiedliche Aufgabenstellungen nutzen. Das Tool ermöglicht es, Filter und Favoriten zu setzen.
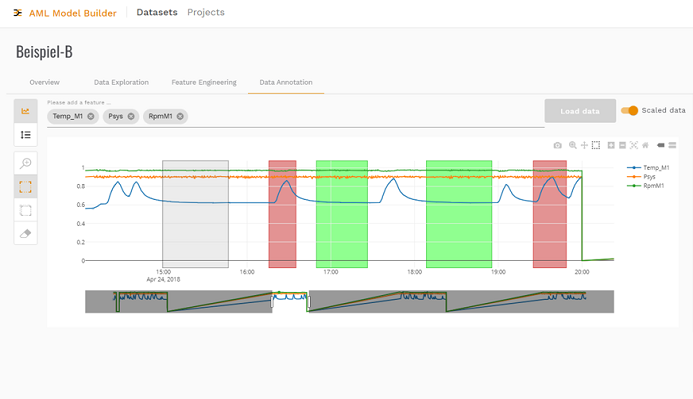
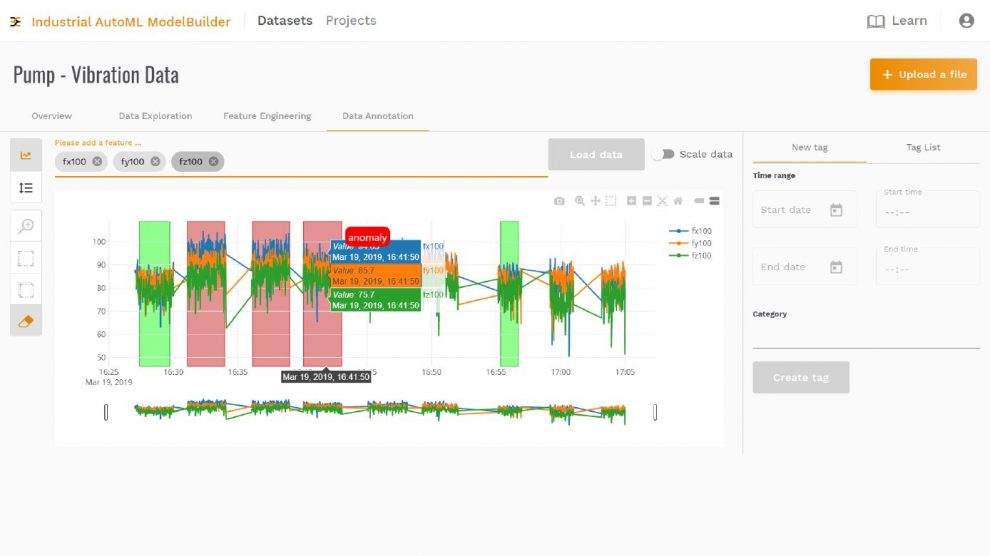
Die Daten werden als CSV-Datei aus einer Steuerung oder dem HMI einer Maschine importiert. Schon dabei ist es sinnvoll, eine Beschreibung der Daten zu hinterlegen. In Folge analysiert die Software im Hintergrund die Eigenschaften der Daten und zeigt beispielsweise die Update-Rate an. Auf dem Dashboard kann sich der Anwender die Sensordaten im Detail anzeigen und ihre Qualität prüfen. Der Anwender kann die Signalverläufe anschauen und dabei Bereiche erkennen, die von besonderem Interesse sind. Er kann auch Kommentare hinterlegen für die spätere Analyse. So sieht er auch, ob er die richtigen Informationen ausgewählt hat, um seine Aufgabenstellung zu erfüllen. Auch lassen sich mittels mathematischer Funktionen zusätzliche Informationen ableiten. Das kann anhand der Rohdaten erfolgen, wie einem Temperaturwert, oder mittels mathematischer Funktionen, um eine Ableitung oder das Quadrat eines Wertes zu bilden. Auf diese Weise lassen sich oft Einflussfaktoren wie Umgebungstemperaturen berücksichtigen, die ein Modell negativ beeinflussen. Die Software zeigt ihm, ob die Daten geeignet sind, ein Modell zu generieren.
Supervised Learning
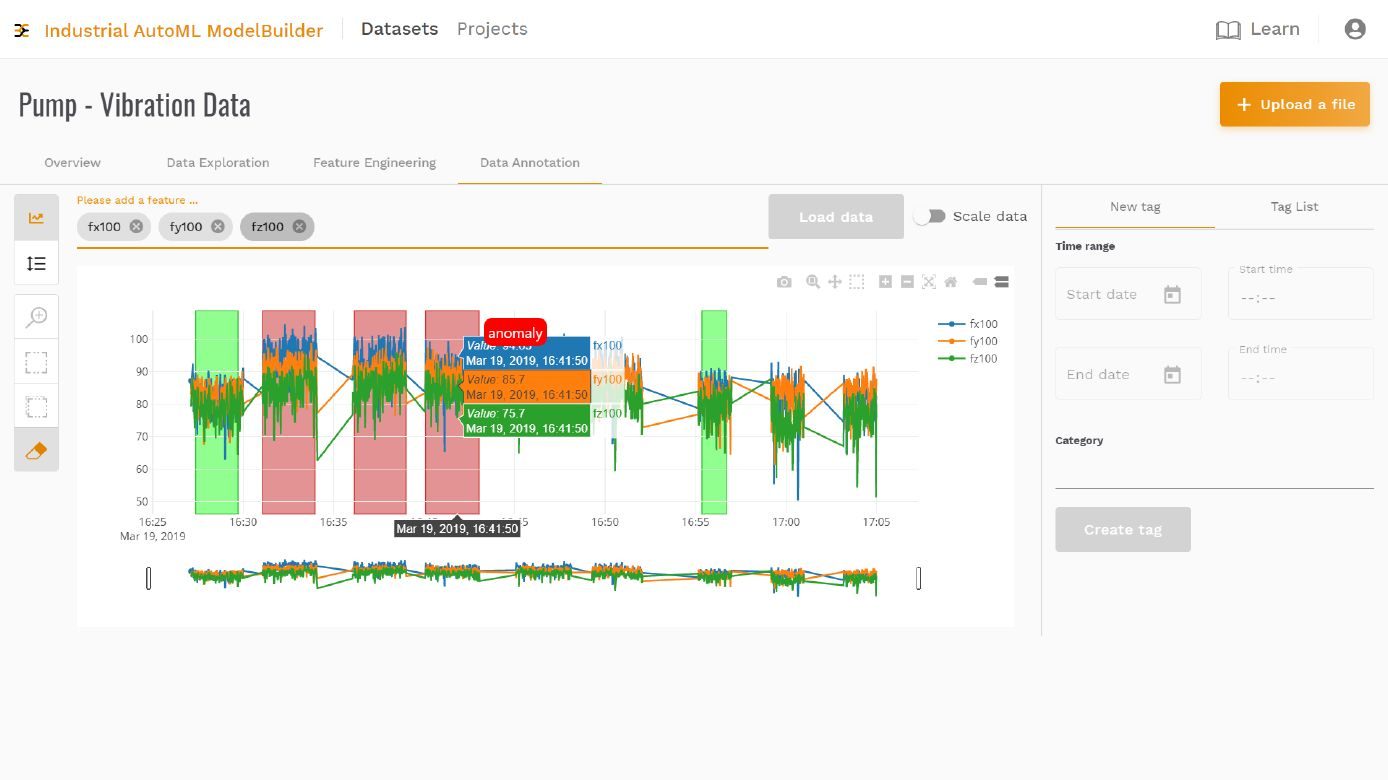
Wichtig ist es, einen Kontext für die Daten zu erstellen. Das wird an einem Beispiel deutlich: Ein Kompressor-Experte kann aus seinen Daten interpretieren, ob die Temperaturwerte des Motors vom normalen Betriebszustand abhängen oder ob ein Fehler im Kühlsystem vorliegt. Steigt die Temperatur des Motors, obwohl der Kompressor einen konstanten Druck erzeugt, kann diese Information als Fehler definiert werden. Der Experte gibt damit Beispiele vor, aus denen ein Maschinenmodell lernen kann. Dieses Supervised Learning wird von AutoML umfassend unterstützt. Die Qualität eines Modells hängt davon ab, wie viele Daten für das Trainieren genutzt werden, aber vor allem von der Qualität der Daten. Sinnvoll ist es, verschiedene Betriebszustände zu definieren, um sie überwachen zu können.
Betreut ein Maschinenbauer verschiedene Projekte beispielsweise für unterschiedliche Maschinenfamilien, lässt sich der Prozess mit Hilfe der Software strukturieren. Innerhalb eines Projekts erstellt das Tool verschiedene Modelle, für die der Domäne-Experte entscheiden muss, ob es sich um einen kontinuierlichen Prozess handelt, ob er eine Antwort des Modells für verschiedene Datenspuren möchte oder ob es sich um einen zyklischen Prozess handelt, für den pro Zyklus eine Antwort gewünscht wird. Innerhalb definierter Kategorien lassen sich Bereiche markieren, die das Normalverhalten darstellen, und Bereiche, die Anomalien widerspiegeln.
Soll beispielsweise ein Anomalieerkennungs-Modell für einen Kompressor erstellt werden, ist es sinnvoll, sich auf die Motoren zu fokussieren. Benötigt werden dazu die Temperaturwerte und eventuell ihre Ableitung. Auch Daten über die Drehzahl der Motoren sind erforderlich, um eine Referenz zu haben, sowie Sensordaten des Drucks, um zu beurteilen, ob der Kompressor seine Funktion optimal erfüllt. Welche Informationen tatsächlich erforderlich sind, liegt in der Entscheidung des Domäne-Experten. Die Software trifft am Ende des Prozesses Aussagen darüber, welche Informationen für die Erzeugung eines Modells wichtig sind.
Start des Trainingsprozesses
Startet der Anwender den eigentlichen Trainingsprozess, erzeugt das Software-Tool im Hintergrund verschiedene Modelle nach unterschiedlichen Kriterien. Der Anwender muss an dieser Stelle prüfen, welches dieser Modelle am besten zu seiner Anwendung passt. Es ist ein großer Vorteil für die Domänenexperten, dass sie überhaupt nicht wissen müssen, welche Algorithmen konkret hinter den Modellen stehen. Die Domänenexperten müssen nur die Modelle, die KPIs und die Feature Importance bewerten. Um die einzelnen Modelle zu trainieren, wird ein Teil der Daten genutzt, um die Modelle zu bewerten, ein weiterer.
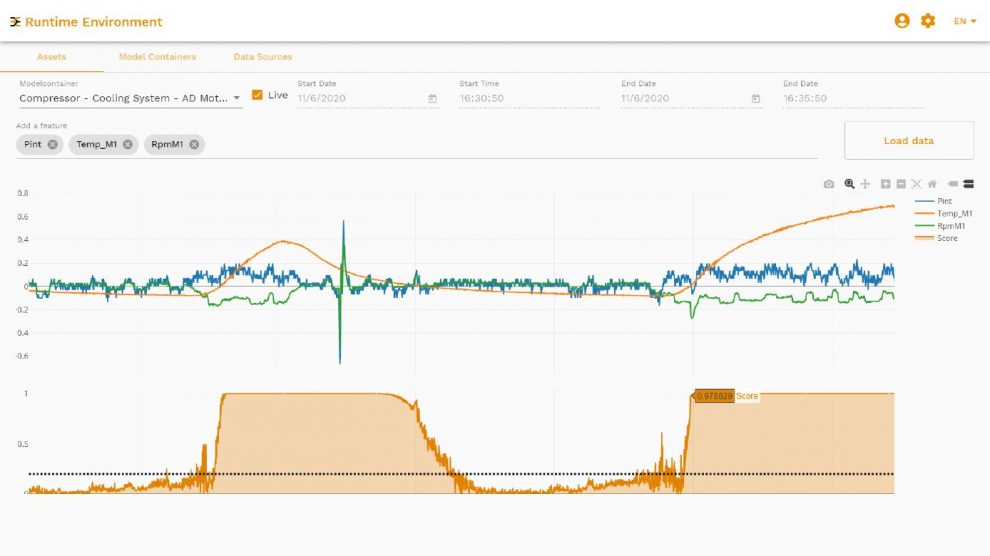
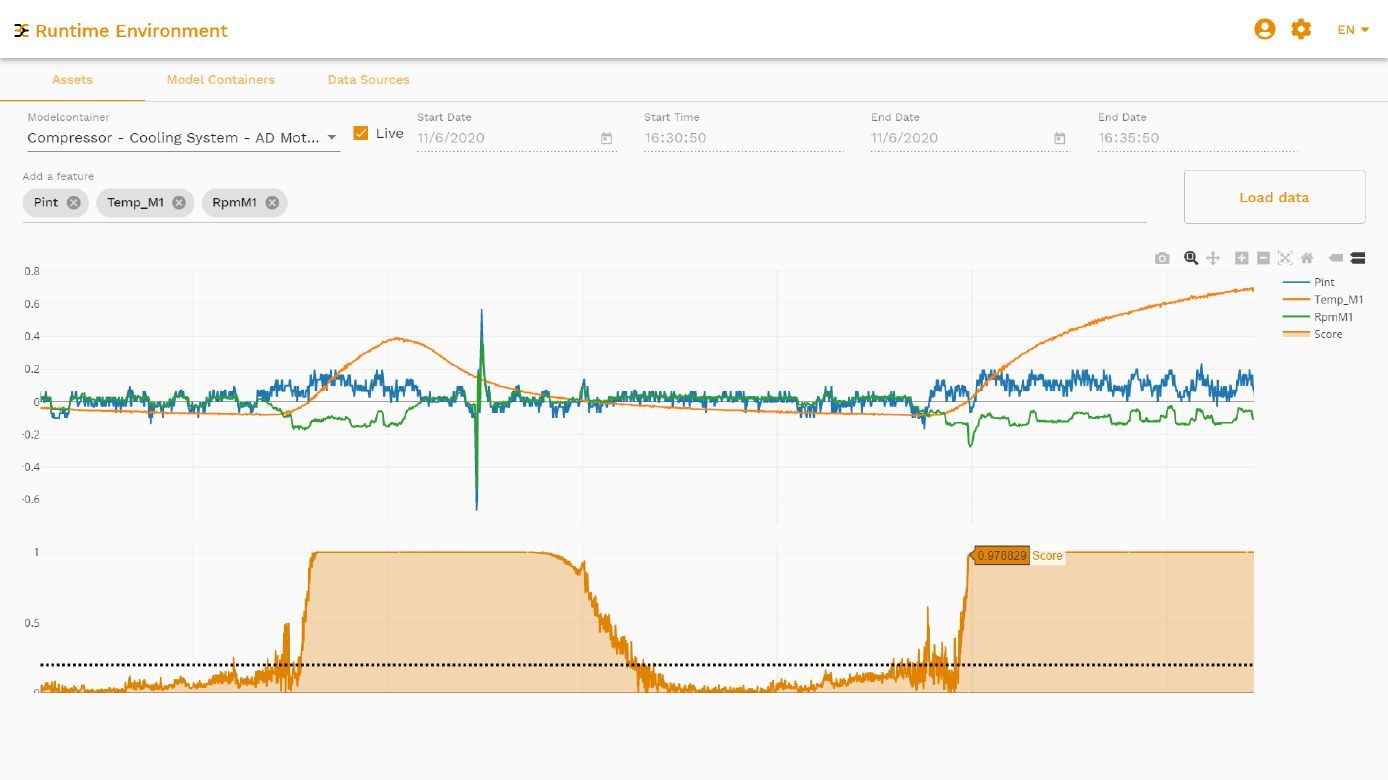
Darüber hinaus gibt die Software Auskunft darüber, welche Rechenressourcen ein Modell benötigt. Das ist entscheidend, wenn nicht nur eine Maschine überwacht werden soll, sondern ein Maschinenpark. Aus den Informationen ist erkennbar, wie lange ein Modell trainiert werden muss, und wie lange es für die Ausführung benötigt. Anhand der Feature Importance kann der Anwender hier erkennen, wie wichtig einzelne Daten die Entscheidung für ein Modell beeinflussen. Am Kompressorbeispiel wird deutlich, dass vor allem die Temperaturwerte sowie die Drehzahl des Motors bedeutend sind, während der Druck keinen wesentlichen Beitrag zur Aussage des Modells liefert. Für andere Algorithmen kann dagegen die Drehzahl wichtiger sein.
Als Anomaly Score werden die Ausgangsdaten eines Anomalieerkennungs-Modells bezeichnet. Dieser Wert signalisiert, ob ein Modell die aktuelle Situation als normal betrachtet oder als Anomalie. Hier lässt sich automatisch ein Schwellenwert berechnen. Dann lassen sich auch Druck-Leckagen am Kompressor als Anomalie erkennen, wenn sie nicht trainiert wurden. Dass ein Anwender nicht an alle möglichen Fehlerscenarien im Vorfeld denken muss, ist eine der wesentlichen Eigenschaften von Machine Learning. Nach dem Training erkennt das Tool auch solche Zustände als Fehler, an die vorher nicht gedacht wurde. Der Anwender kann sich Datengetrieben auf das Normalverhalten konzentrieren und dabei sicher sein, dass das Modell die Fehler trotzdem erkennt. Hat sich ein Maschinenbauer für ein bestimmtes Modell entschieden, kann er es exportieren.
Industrial AutoML ModelRuntime
Zur Auswertung mit der ModelRuntime muss zuerst eine Datenquelle definiert werden. AutoML unterstützt verschiedene Optionen. Die zu analysierenden Daten können aus einer Datenbank geladen oder mittels OPC UA aus einer Steuerung importiert werden. Die Datenbank kann beispielsweise auch auf einem Edge-Device an einer Maschine laufen. Mittels OPC OPC Data Access lassen sich Daten in Echtzeit aus dem Prozess laden. Auch OPC Historical Data Access lässt sich nutzen, um archivierte Prozessdaten auszutauschen. Die Runtime in der Cloud bietet verschiedene Vorteile. So sind z.B. skalierbare Szenarien möglich, um eine größere Zahl von Maschinen zu überwachen. Dann kommen andere Technologien zum Einsatz, die entsprechend optimiert sind und flexibel skaliert werden können.
Die Runtime stellt die Roh- bzw. Sensordaten im Zeitverlauf auf einem Dashboard dar, ähnlich wie im ModelBuilder. Das Modell erkennt in Echtzeit, ob es sich um normale Betriebs- oder nicht normale Situationen handelt. Auch hier lassen sich die Information so nacharbeiten, dass ein Maschineneinrichter beispielsweise diese Information optimal interpretieren kann. Dafür lassen sich Tools wie Procon Web nutzen, das ist ein weiterer Software-Baustein von Weidmüller. Anwender können eine Applikation definieren und anhand dieser Modellergebnisse beispielsweise ein HMI, ein Dashboard oder eine Ampel einrichten, die Auskunft über die aktuellen Werte geben.
Aufgaben der Qualitätssicherung automatisieren
Für Szenarien, die eine kurze Reaktionszeit erfordern, ist es möglich, mittels OPC UA Informationen direkt aus einer Steuerung zu laden. Doch nicht immer sind kurze Reaktionszeiten erforderlich. Oft benötigt der Anwender Informationen, die zwar zeitnah erzeugt werden, aber vor allem kontinuierlich verfügbar sind. Aber es gibt auch langsame Prozesse, wie der Verschleiß an Motoren. Die Ausfälle ergeben sich nicht sofort, sondern folgen erst nach einiger Zeit. Das gilt generell für den Verschleiß mechanischer Komponenten. Hier möchte der Anwender die Information bekommen, wann er die Maschine warten sollte, um eine Störung zu vermeiden. Bei der Nutzung des Machine Learnings stehen vor allem Qualitätsaspekte im Vordergrund. Die Anwender möchten sicherstellen, dass die Maschinen laufen und kontinuierlich Qualität produzieren.
Maschinenbauer werden zukünftig mehr Services anbieten. Bei der Einführung neuer Geschäftsmodelle wird die Zusammenarbeit mit den Endanwendern enger. Probleme, die bisher der Anwender lösen musste, werden nun zu Aufgaben der Maschinenbauer. Machine Learning wird zu einer Basis dafür, dass solche Geschäftsmodelle für Maschinenbauer attraktiv werden, mittels Machine Learning sind sie in der Lage, Aufgaben der Qualitätssicherung zu automatisieren.
Predictive Maintenance
Neben diesen Anomalieerkennungs-Modellen gibt es weitere Modelle bzw. Modelltypen, z.B. Klassifikationsmodelle. Das sind komplexere Modelle, die nicht nur die Information liefern, dass eine Abweichung vom normalen Verhalten vorliegt, sondern sie ordnen einem Zustand eine Fehlerklasse zu, beispielsweise einen Lagerschaden. Prädiktionsmodelle liefern die Information, dass eine Situation in einem bestimmten Zeithorizont auftreten wird, sodass sich Wartungsaufgaben planen lassen. Häufen sich Anomalien, lässt sich auch daraus die Planung der Wartung ableiten. Modelle für das Predictive Maintenance setzen eine hohe Daten-Qualität voraus. Benötigt werden nicht nur die Information, wie ein Fehler konkret aussieht, sondern erforderlich sind auch Informationen über die zeitliche Entwicklung des Fehlers. Für die Erzeugung solcher Modelle ist es unerlässlich, Daten über einen langen Zeitraum zu erfassen.
Hier finden Sie mehr über:




{kind=link}